Core idea
When a model processes language, not every earlier word is equally useful. Attention gives the model a way to assign larger weight to the most relevant tokens at each step, instead of treating all context the same.
Why attention was introduced
Early encoder-decoder systems squeezed an entire input sentence into one fixed vector before decoding. That created an information bottleneck, especially for long inputs. Attention fixed this by letting the decoder look back at all source representations and focus on the parts that matter for the current output token.
Query, key, value
Think of attention as a learned lookup process. Every token produces three things:
- Query: what the current position is looking for.
- Key: a descriptor other positions use to say "I have this".
- Value: the actual content that gets mixed in if a match is strong.
The model compares the query against all keys to get relevance scores, converts those scores into weights using softmax, then takes a weighted sum of the values. Higher score means more of that token's value flows through.
Current token | v compare query against all keys → relevance scores | v softmax → weights that sum to 1 | v weighted sum of values → context-aware representation
Attention is soft: the model distributes probability mass across many tokens rather than picking one with a hard yes/no rule.
Types of attention and where they appear
| Type | What attends to what | Where it is used |
|---|---|---|
| Self-attention | A sequence attends to itself — every token looks at every other token in the same sequence. | Transformer encoder layers (e.g. BERT). Each word learns how it relates to every other word in the sentence. |
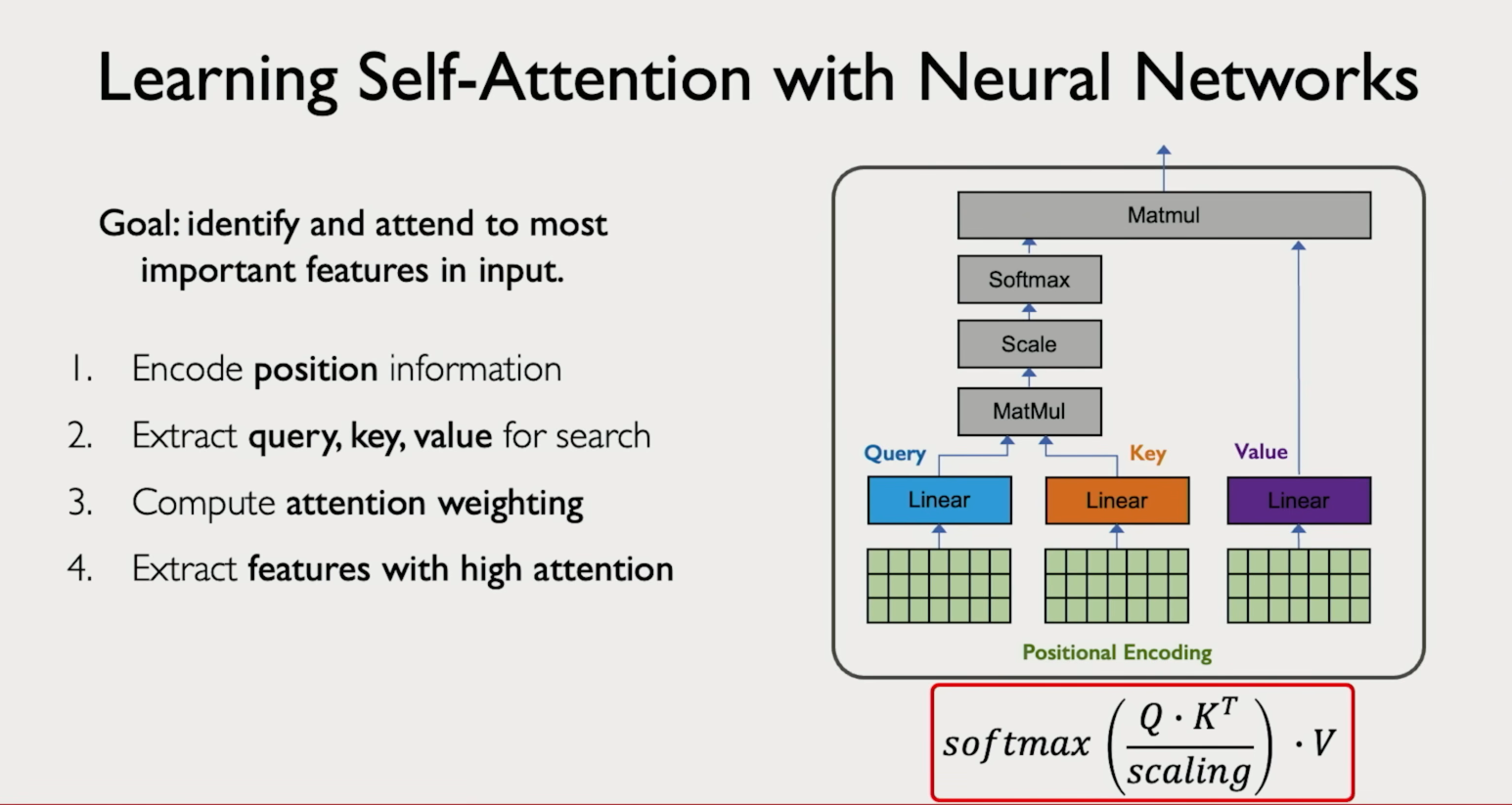
|
||
| Cross-attention | One sequence attends to a different sequence — queries come from the target, keys and values come from the source. | Encoder-decoder models like T5 or classic machine translation. The decoder looks at all encoder outputs to decide what source content to use next. |
| Causal (masked) attention | Each position can only see itself and earlier positions — future tokens are blocked. | Autoregressive language models like GPT. Ensures the model can only use past context when predicting the next token. |
Multi-head attention
A single attention pattern is often too limited to capture everything useful. Multi-head attention runs several attention operations in parallel, each in its own subspace. Different heads specialize in different relationships — one might track local syntax, another long-range dependencies, another coreference. Their outputs are concatenated and projected back to the model dimension.
Advanced
At advanced depth, attention is best understood as a family of mechanisms with different scoring functions, efficiency trade-offs, and failure modes. The central questions are how relevance is scored, what information flow is permitted, and what cost is paid as context grows.
Additive vs dot-product attention
| Form | Idea | Typical note |
|---|---|---|
| Additive attention | Uses a small learned feed-forward scorer over the query and key. | Associated with early encoder-decoder attention such as Bahdanau. More flexible but slower. |
| Dot-product attention | Uses vector dot products for similarity, scaled by the square root of the key dimension to keep scores stable. | Efficient on modern hardware and the standard in transformers. |
Masking controls visibility
- Padding mask: hides padded positions so fake tokens do not influence real ones.
- Causal mask: blocks future tokens during autoregressive generation.
- Task-specific masks: restrict visibility according to structure, locality, or design choices.
Q × K^T → raw scores raw scores + mask → blocked positions get large negative values softmax → normalized weights weights × V → output
Cost on long sequences
Full self-attention compares every token against every other token, so the score matrix has n × n entries. Memory and compute grow quadratically with sequence length — doubling the sequence roughly quadruples the cost. This is why long-context NLP is hard.
Efficiency approaches
- Local or sparse attention: not every token attends to every other token.
- Multi-query attention (MQA): many query heads share one key/value set, reducing KV memory.
- Grouped-query attention (GQA): multiple query heads share groups of key/value heads. Used in Llama 2 and later.
- FlashAttention: computes exact attention with more efficient memory movement by tiling operations instead of materializing large intermediate matrices.
What attention weights do and do not tell you
Attention maps can be informative, but they are not a complete explanation of why a model made a decision. A token may receive high weight yet not be the only cause of the final output. Residual connections, MLP layers, and layer stacking all affect the result. Attention is useful evidence, not a full causal explanation.
Common failure modes
- Diffuse attention: focus spreads too broadly and weakens signal.
- Over-concentrated attention: one token dominates and useful context is ignored.
- Position sensitivity: models can still struggle when dependencies are very long or structurally unusual.
- Cost explosion: long sequences make full attention expensive even when conceptually ideal.
A good mental model: attention is a content-addressable routing mechanism. It decides which stored representations should influence the current token and by how much.
Practice
- Work through a tiny attention example by hand and compute the softmax weights.
- Draw a toy attention matrix and mark which entries are blocked by a causal mask.
- Explain in your own words how multi-head attention differs from single-head attention.
- Compare additive attention and dot-product attention in one paragraph.
- Estimate how attention cost changes when sequence length doubles.
Build
- Create a small script that computes scaled dot-product attention for toy vectors.
- Build a visualization that shows how a causal mask changes the attention matrix.
- Write a short note explaining when self-attention and cross-attention are used.
- Summarize one long-context efficiency idea such as sparse attention, MQA, GQA, or FlashAttention.
- Make a one-page cheat sheet of the attention formula, shapes, and mask types.